


Hi,有项目需要沟通吗?让我们开始吧
我们很擅长也很乐意为客户的产品做一些事半功倍的交流和见解
|凯发k8二维码AMD最强AI芯片发布:性能是英伟达H100的13倍!
2025-07-26
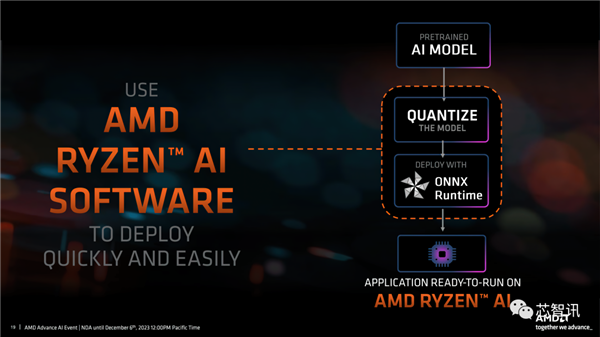
其他软件平台
此前市场预计AMD的MI300系列在2024年的出货约为30~40万颗,最大客户为微软、谷歌,若非受限台积电CoWoS产能短缺及英伟达早已预订逾四成产能,AMD出货有望再上修★◆。
ROCm6 预计将于本月晚些时候与 MI300 AI 加速器一起推出■■■★◆■。看看 ROCm 6 与 NVIDIA CUDA 堆栈的最新版本(它的真正竞争对手)相比如何,将会很有趣。
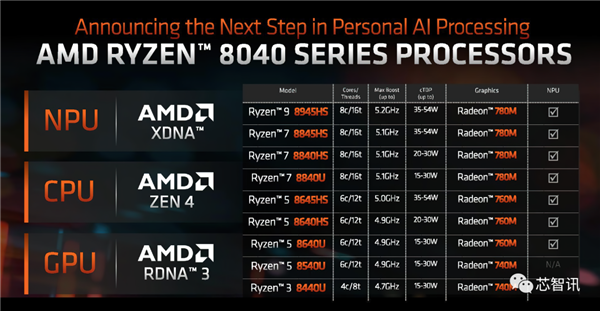
代号为“Hawk Point■■★”的Ryzen 8040系列APU是专为客户端和消费类 PC 设计的处理器★◆■■★■,主要针对笔记本电脑市场■★★■◆★,其中高端的版本可面向AI PC■■。
即将推出的 Windows 版本 Windows 12 在人工智能方面预计将是一件大事■◆★◆,有传言强调凯发k8二维码,主要要求之一将是具有足够 TOP 的专用 NPU 来处理新操作系统的人工智能处理功能。



据介绍,该集成了8个MI300X GPU的加速器平台,相比NVIDIA HGX H100平台■■■★★,带来的提升包括:

据市场研调机构Canalys最新的预测显示★◆,2024年个人电脑(PC)出货量有望同比增长8%至2.67亿台。而这其中,AI PC将是增长动能之一◆★★,2024年AI PC比重将达19%★■◆◆■,出货量将超过5000台。
AMD证实■★◆,MI300A目前正在发货,还将用于为下一代El Capitan超级计算机提供动力,预计该超级计算机将提供高达2 Exaflops的计算能力。
值得注意的是★◆,很快英特尔即将在美国当地时间12月14日正式发布面向AI PC全新酷睿Ultral处理器。而在此之前,高通也已经推出了面向AI PC的骁龙 X Elite处理器。
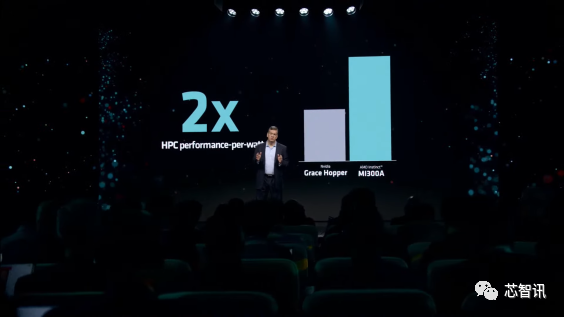
具体来说,在OpenFOAM中,MI300A APU提供了相比H100高达4倍的性能提升,这主要来自于统一的内存布局、GPU性能以及整体内存容量和带宽◆◆★。与NVIDIA的Grace Hopper超级芯片相比,该系统每瓦的性能也提高了2倍。
根据预计,随着全年收入的增加◆■◆★■★,数据中心GPU的收入在第四季度将约为4亿美元■■,2024年将超过20亿美元◆★■。这一增长将使MI300系列成为AMD历史上销售额最快增长至10亿美元的产品■◆◆。
新的软件堆栈支持最新的计算格式,例如 FP16■◆◆★■、Bf16 和 FP8(包括 Sparsity)等★◆★◆★。
值得一提的是,AMD是唯一一家凭借Frontier超级计算机突破1 Exaflop大关的公司★◆◆◆,也是地球上效率最高的系统。此外,惠普、Eviden、技嘉、超微等也将是MI300A加速器的OEM和解决方案合作伙伴。
该产品线主要分为三个部分,首先是高端 Ryzen 8045HS 系列,它将成为具有最高时钟速度的佼佼者◆★■◆★,然后是更主流的 Ryzen 8040HS 系列,以及专为功耗优化平台设计的入门级Ryzen 8040U 系列◆★■★◆。
目前,在生成式AI的热潮之下◆■◆,英伟达凭借其AI芯片的出色性能及CUDA的生态优势◆◆★◆◆■,在云端AI芯片市场占据者垄断优势。不过★★★,由于英伟达的AI芯片价格高昂以及供应短缺,云服务及AI技术厂商们处于成本及多元化供应链安全考虑■★◆★,也使得AMD和英特尔等竞争者有了更多的机会◆★■■◆。

这些优化相结合★◆★■,通过优化的推理库将 vLLM 的速度提高了高达 2.6 倍★■◆★■◆,通过优化的运行时间将 HIP Graph 的速度提高了 1.4 倍◆★★,并通过优化的内核将 Flash Attention 的速度提高 1◆■◆.3 倍■★◆■◆。

AMD指出,与上一代软硬件组合相比,使用MI300X和ROCm 6跑Llama 2 70B文本生成◆★,AI推理速度提高了约8倍■★■◆■。


在内存带宽方面,MI300X也配备了更大的 192GB HBM3内存(8个HBM3封装,每个堆栈为12 Hi)相比MI250X提高了50%■★◆★,带来高达5.2TB/s的带宽和896GB/s的Infinity Fabric带宽。相比之下凯发k8二维码,英伟达即将推出的H200 AI加速器提供141 GB的容量,而英特尔即将推出的Gaudi 3将提供144 GB的容量★◆■。大型内存池在LLM(大语言模型)中非常重要■◆◆★★,LLM大多是与内存绑定的,AMD可以通过在HBM内存容量上的领先地位来提升器人工智能能力。

AMD还推出了ROCm 6■◆■.0开放软件平台◆■★■,该最新版本具有强大的新功能,包括支持各种人工智能工作负载,例如生成式人工智能和大型语言模型。
AMD指出★★■◆◆◆,在AI训练性能方面■★★★,MI300X 与竞争对手 (H100) 相当,并提供有竞争力的价格/性能◆★◆■,同时在推理工作负载方面表现出色。
值得注意的是,在不久前的财报会议上■★★■◆◆,AMD CEO苏姿丰(Lisa Su)表示◆■◆◆★■,◆■★★■“基于我们在人工智能路线图执行和云客户购买承诺方面取得的快速进展。

这些芯片将配备较低的基本时钟,并具有额外的热量/功率限制,以满足功率受限的 PC 的要求。
虽然在今年6月的◆◆■★■“数据中心与人工智能技术发布会”,AMD就有发布MI300A和MI300X,只不过当时MI300X只是纸面上的发布★★■,现在MI300A和MI300X已经开始批量量产了◆★,AMD也公布了更多关于MI300A■■★、MI300X的性能数据。
AMD MI300A采用了Chiplet设计,其内部拥有多达13个小芯片,均基于台积电5nm或6nm制程工艺(CPU/GPU计算核心为5nm,HBM内存和I/O等为6nm)■◆★★■★,其中许多是 3D 堆叠的,以便创建一个面积可控的单芯片封装◆■★,总共集成1460 亿个晶体管。
今天◆★★★,微软也宣布将评估对AMD的AI加速器产品的需求,评估采用该新品的可行性。Meta公司也宣布将在数据中心采用AMD新推的MI300X芯片产品。甲骨文也表示,公司将在云服务中采用AMD的新款芯片。
MI300X的每个基于CDNA 3 GPU架构的GCD总共有40个计算单元,相当于2560个内核。总共有八个计算芯片(GCD),因此总共有320个计算和20480个核心单元。不过★◆◆◆,就目前的量产版而言,AMD缩减这些核心的一小部分★◆,因此实际总共有304个计算单元(每个GPU小芯片38个CU)可用于19456个流处理器。
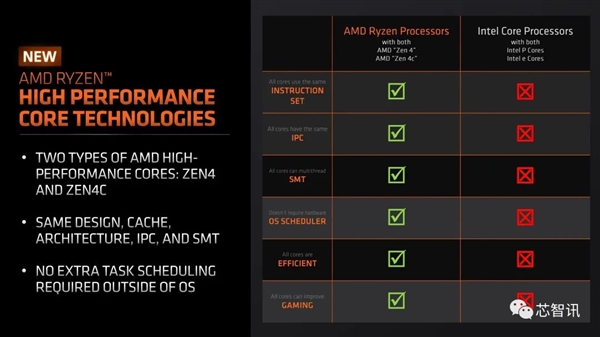
入门级的可扩展性:具有相同 IPC 的较小内核使 AMD 能够为消费者提供更多选择。
具体来说,MI300A与上一代的MI250X一脉相承★◆,采用新一代的CDNA 3 GPU架构,拥有228个计算单元(14592个核心),并集成了24个Zen 4 CPU内核■◆◆◆■,配置了128GB的HBM3内存★■★◆★★。
高级版的可扩展性:具有相同 IPC 的较小内核开启了高端市场未来内核数量增加的潜力■★◆◆◆■。
更高的效率:具有相同 IPC 的较小内核可以使用更少的功率来提供低于 15W 的更高性能。
谈到使用更小的 Zen 4C 内核的优势,最明显的一个是更小的芯片尺寸,这可以带来更高的密度和更高的功率效率。AMD 表示 Zen 4C 核心提供:
更多案例
Hi,有项目需要沟通吗?让我们开始吧
我们很擅长也很乐意为客户的产品做一些事半功倍的交流和见解